Werbefrei,
für immer!
Fortigate Cluster Out of Sync
Hilfe, das Cluster ist out of Sync!
Fehlerbild
Im Dashboard ne Warnung und im HA Status ein rotes Kreuz beim Secondary, das sieht nach einem „Out of Sync“ aus.
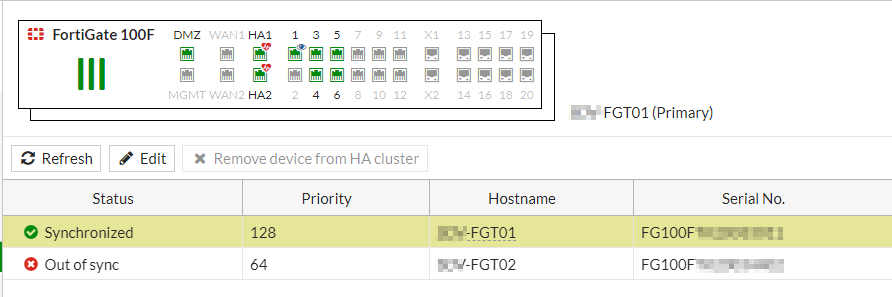
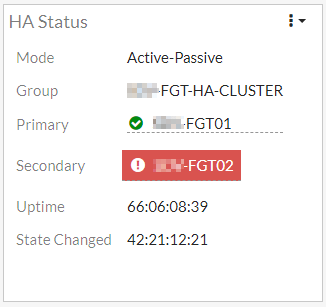
Checksum
Ok, dann prüfen wir das via SSH anhand der Prüfsummen:
Globaler Vergeich beider Units mit:
diag sys ha checksum clusterJetzt der Vergleich auf den einzelnen Units.
Beachte! Bis Firmware Version 5.2.x und älter…
get system checksum statusgibt uns die Prüfsumme der Primary Unit, welche immer identisch zur Secondary sein sollte.
Also sehen wir uns jetzt noch die Prüfsumme der Secondary Unit an, auf der wir uns hierfür separat anmelden (Je nach ID ist die 1 evtl. mit einer „0“ zu ersetzen):
execute ha manage 1 <Admin-Benutzername>get system checksum status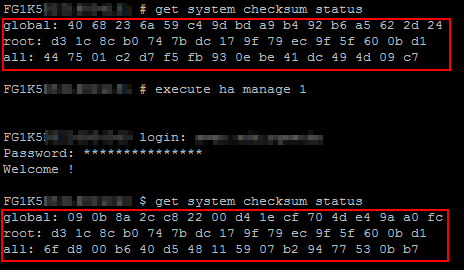
ACHTUNG! Ab Firmware Version 5.4…
Hier funktioniert die Abfrage Checksums für beide Nodes direkt auf dem Primary:
diagnose sys ha checksum clusterBeispiel fehlerhafter Prüfsummen: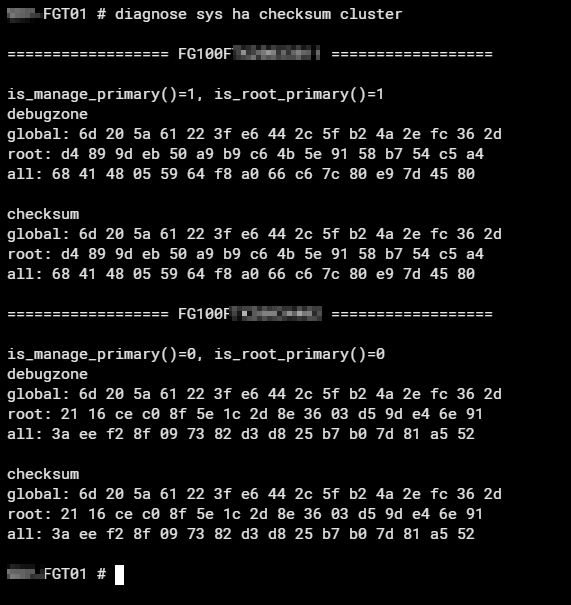
Beispiel eines 200er Cluster, korrekt im Sync…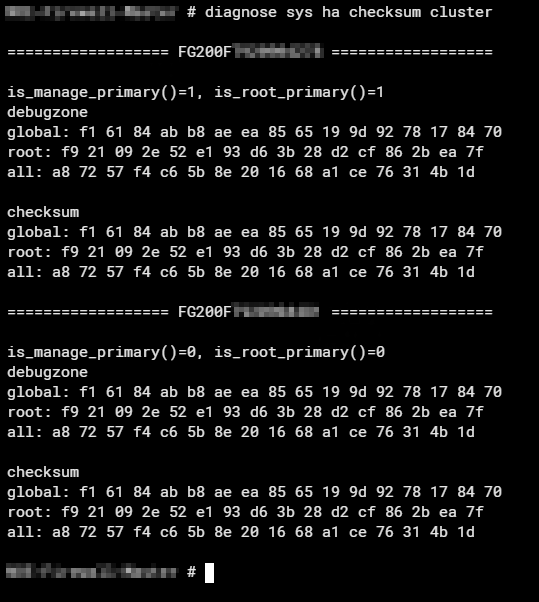
Interessant ist hier primär die „all:“ Zeile und die passt im Beispiel oben nicht. Bei einer sauber synchronisierten Konfiguration, stimmen die Prüfsummen alle exakt überein, wie im unteren Screenshot zu sehen ist.
Der Sache müssen wir auf den Grund gehen…
Neuberechnung der Checksum initiieren
Zuerst initiieren wir eine Neuberechnung der Prüfsumme auf dem Primary:
diagnose sys ha checksum recalculateund prüfen erneut:
diagnose sys ha checksum cluster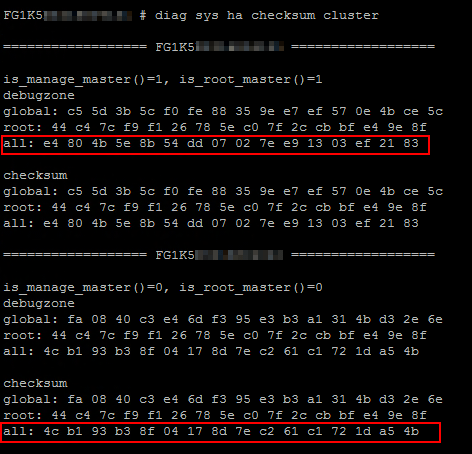
Ok, das war’s auch nicht und hat bei mir persönlich auch nie wirklich geholfen.
Die Frage nach dem Log der Synchronisierung beantworten wir jetzt:
Kurversion: Stoppen der Synchronisation am Primary, Debug Trace (Troubleshooting) vorbereiten und dann den Sync starten…
execute ha synchronize stop
diag debug reset
diag debug enable
diag debug console timestamp enable
diag debug application hasync -1
diag debug application hatalk -1
execute ha synchronize startIn der Ausgabe sind eventuell Fehler bei der Verbindung oder andere Umgereimtheiten zu entdecken. Diese Ausgabe kann u.U. auch vom Support eingefordert werden, wenn ein Ticket eröffnet wurde.
System Disks prüfen…
Gerne spinnt ein Cluster Member, wenn die lokale Disk defekt ist. Hat die Appliance keine lokale Disk, kann man sich das natürlich sparen. Also den Disk Status auf beiden Appliances prüfen mit:
get sys status
exec disk listSollte alles nichts nützen kann versucht werden, die beiden Konfigurationen der Systeme manuell anzugleichen.
Manuell die Konfiguration abgleichen
Um die Ausgaben von irgendwelchen --- More --- Zeilen zu verhindern, via SSH am Primary:
config system console
set output standard
endDann bei Putty die Log Ausgabe einschalten, „Printable“ Output aktivieren und das Ganze in eine Datei bspw. primary-config.log schreiben.
Mit einem simplen
showerscheint nun die „Running Config“ und wird ins File umgeleitet…
Direkt danach das Putty Log wieder auf none umstellen, um Müll im Log zu vermeiden…
Jetzt wieder mit
execute ha manage 1auf die Secondary Unit wechseln.
Nun wieder am Putty die Logging Ausgabe einschalten, das Ganze in eine Datei bspw. secondary-config.log umleiten und „Printable“ Output aktivieren.
Mit einem simplen
showerscheint nun die „Running Config“ und wird ins File secondary-config.log geschrieben…
Im Notepadd++ das Plugin „Compare“ installieren und die Primary Config öffnen. Mit Strg+Alt+1 markiert man das File primary-config.log als „First to Compare“.
Jetzt die Datei secondary-config.log öffnen und mit Strg+Alt+C vergleichen.
Die unterschiedlichen Stellen werden nun hervorgehoben.
Ignoriert werden können:
- hostname
- SN
- interface dedicated to management
- password hashes,
- certificates
- HA priorities und override settings
- disk labels
Alles andere sollte nach Möglichkeit identisch sein.
Achtet auf Umlaute und sonstige ASCII Zeichen, egal wo! Oft waren diese eine Ursache für merkwürdige Fehler, da die Konfig nicht sauber übernommen wurde.
Das gilt übrigens immer, speziell vor Firmware Updates!
Manuell die Cached Configs der Systeme auf Unterschiede prüfen
Hier lässt man sich quasi die Config Zeilenweise ausgeben, welche auf den Units aktiv ist und vergleicht diese mit einem Programm wie Notepadd++ und der Erweiterung „Compare“…
Login an der Primary Unit, dann:
diag sys ha checksum cached globalJetzt direkt im Putty alle Zeilen kopieren und in einer Datei speichern…
Login an der Secondary Unit und wieder:
diag sys ha checksum cached globalJetzt wieder direkt im Putty alle Zeilen kopieren und in einer weiteren Datei speichern…
Jetzt beide Files mit einem Programm vergleichen. Unterschiede könnten so aussehen:
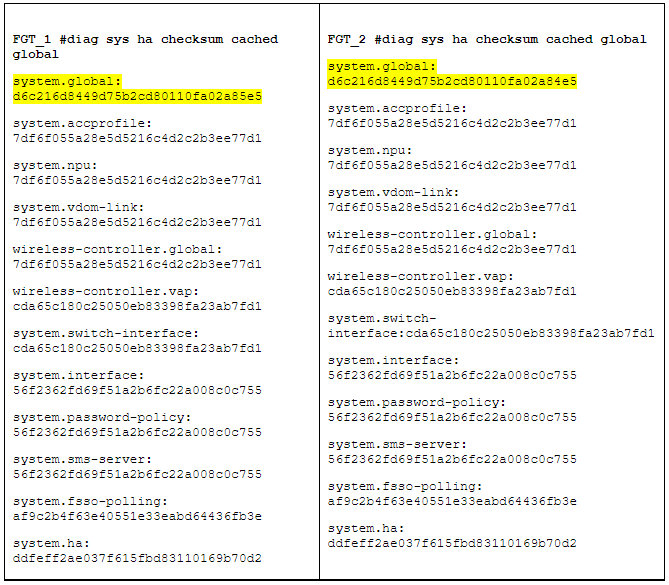
Wie man sieht, ein Unterschied in den globalen Settings, also detailliert prüfen mit:
diag sys ha checksum show global system.globalIm Beispiel eine Abweichung in den Timeout Settings des Admins, die man jetzt im Zweifel manuell anpassen kann…
Das Ganze jetzt noch einmal mit Checksum für die „root dom“ und wieder auf beiden Units…
diag sys ha checksum cached rootWieder beide Files vergleichen und Unterschiede prüfen…
Sollte das alles fehlschlagen, hilft nur noch der Holzhammer und man muss jetzt physisch, mit Konsolenkabel, direkt ans Secondary System!
Disjoin und Rejoin der Secondary Appliance
Dies ist im Übrigen die letzte Möglichkeit, die auch der Support empfiehlt, wenn alle anderen Methoden fehlschlagen und die Festplatten ok sind. Hat man physischen Zugriff auf das System, ist das auch kein Problem und im laufenden Betrieb, ohne Downtime möglich. Aber Achtung! Diese Aktion nur durchführen, wenn man physischen Zugriff auf die Appliances hat!
Also Konsolenkabel an die Secondary Unit und jetzt die Secondary Unit via GUI aus dem Cluster entfernen.
Dann versetzt man das System in den Auslieferungszustand und startet mit der Netzwerk-Konfig bei NULL…
execute factory reset
config system interface
edit [Portname]
set ip [IP Adresse] [Subnetz Maske]
set allowaccess ping https ssh httpDamit sollte man jetzt via SSH ans System kommen, was uns völlig reicht, wenn die HA Ports noch miteinander verbunden sind.
Achtung, vor dem Cluster Join der Secondary prüfen, dass am Secondary KEIN Interface seine IP Adresse via DHCP bezieht, also im Zweifel alle anderen Interfaces auf „manual addressing“ und die Interface IP auf 0.0.0.0/0 (default) setzen.
Dann die Secondary wieder via GUI ins Cluster aufnehmen und ein paar Minuten den initialen Sync des Clusters abwarten. Die Appliance sollte jetzt in jedem Fall wieder erfolgreich synchronisiert werden. Sollte dem nicht der Fall sein, hilft nur noch der Fortinet Support weiter…
[…] redundant und online sind. Sollte das Cluster „Out of Sync“ sein, hilft vielleicht mein Troubleshooting Artikel etwas bei der […]